Beyond the Browser: Benchmarking the Next Generation of Enterprise AI Agents
Insights
April 15, 2025
April 15, 2025
Senthil Kumaran Kandasamy
Lakshmi Vanaja Chinnam
Jyostna Parasabaktula
Shyamkrishnan Adissamangalam
Shalini Padma
Amal Raj
Prasenjit Dey
SVP Innovation
Introduction
The landscape of artificial intelligence is rapidly evolving, with agentic systems capable of interacting with digital environments taking center stage. Systems ranging from Anthropic's Computer Use model, capable of operating applications based on natural language [1], OpenAI's Operator [2], H Company's H-Runner [3], to Emergence's Agent-E [4] demonstrate remarkable abilities to operate software, browse the web, and utilize tools. These systems mark a shift from passive language interfaces to autonomous agents capable of goal-directed action — operating software, navigating digital environments, and completing multi-step workflows that traditionally required human supervision.
To measure the progress and capabilities of these agents, a diverse ecosystem of benchmarks has emerged. Benchmarks like WebVoyager [5] and WebArena [6] operate in sandboxed environments or are focused on the open web – to evaluate proficiency in general web navigation and interaction. Others, like AssistantBench [7], test agents on more complex, long-horizon tasks that mimic real-world utility. Concurrently, specialized benchmarks assess crucial component skills: AgentBench [8] evaluates general reasoning and tool-use capabilities, while Spider [9] (and its more complex successor Spider-V) focuses on the complex task of text-to-SQL generation, a skill relevant for data interaction in many enterprise contexts. The field is also expanding to evaluate agents in highly specialized domains, with benchmarks like PaperBench [10] testing AI research replication and MLGym [11] focusing on automating machine learning tasks. While benchmarks such as ST-WebAgentBench [12] are beginning to address enterprise concerns like safety and trustworthiness, the primary focus of most web-centric benchmarks remains on consumer-oriented scenarios or isolated capabilities.
The Enterprise Gap: Why Existing Benchmarks Fall Short
While valuable for assessing general capabilities or specific skills, this existing benchmark landscape often falls short of capturing the unique challenges and integrated requirements of typical enterprise workflows. Enterprise environments present a distinct and often more challenging set of hurdles compared to the open web or sandboxed tasks. Consider seemingly straightforward tasks common in many organizations:
Creating an IT Support Ticket: This is not just filling in a form. It often involves navigating a complex ITSM platform (e.g., JIRA Service Management, ServiceNow), authenticating securely (potentially with MFA), selecting appropriate categories from enterprise-specific taxonomies, and potentially linking to internal knowledge base articles.
Checking and Responding to Email: Beyond simple reading/writing, enterprise email use involves navigating corporate security policies, using specific formatting, interacting with calendar integrations, and potentially triggering automated workflows.
Creating Documentation: Drafting a document might require researching information on the internal network or specific databases, adhering to company templates stored in systems like Confluence or SharePoint, and managing version control and access permissions.
These examples highlight that even browser-based enterprise tasks often carry significantly more contextual complexity, stricter process adherence, and integration dependencies than typical open-web tasks.
Furthermore, enterprise environments introduce critical operational barriers not typically modeled in consumer benchmarks:
Authentication & Credentials: Accessing enterprise systems requires valid, often dynamically managed, credentials and robust authentication mechanisms (SSO, MFA), posing a significant initial hurdle for autonomous agents.
Multiple Execution Paths: Crucially, many enterprise tasks offer multiple ways to achieve the same outcome. An agent could interact with the graphical user interface (GUI) via browser automation, mimicking human actions. However, a more efficient and robust path often exists via Application Programming Interfaces (APIs). For instance, creating a JIRA ticket can be done through the web UI or directly via the JIRA REST API.
This duality presents a challenge and an opportunity. Agents relying solely on UI automation can be brittle (sensitive to UI changes) and slow. Agents capable of leveraging APIs can be significantly faster, more reliable, and less prone to errors caused by superficial UI updates. Therefore, AI agents designed for the enterprise must evolve beyond simple browser interaction to intelligently select and utilize the most appropriate tools, including APIs.
EEBD: A New Benchmark for Enterprise Tasks
To systematically study agent capabilities in realistic enterprise scenarios and evaluate their ability to leverage different execution paths, we developed a first release version (v1) of the Emergence Enterprise Benchmark Dataset (EEBD). EEBD-v1 comprises 45 tasks designed to mirror common enterprise workflows. EEBD-v1 captures an initial version of Layer 1 and Layer 2 of the layered, cross-application workflows [detailed in "Layer by Layer: A Structured Approach to Benchmarking AI Agents in the Enterprise"] that characterize real enterprise operations — requiring agents to combine open-ended research, authentication-aware platform use, structured documentation, and process adherence in a single task. Below are a few illustrative examples:
Identifying the top 5 fintech innovators in Africa, highlighting company name, official website, financial services offered, and their primary country of operation, then storing and arranging all relevant information in a Confluence table.
Going to Zoom’s official status page to check the latest reported outages or incidents, creating a JIRA Epic titled "Monitor Zoom Outages," adding subtasks for each incident, and linking the status page in the JIRA description.
Visiting the official Slack blog to see newly announced integrations, creating a JIRA Task to evaluate each integration for internal use, and then opening a "New Integrations" page in Confluence summarizing key integration details.
Many EEBD-v1 tasks are multi-step and compound, requiring agents to integrate information across different applications (e.g., research on the web, then document in Confluence).
Methodology: Testing Leading Agents
We evaluated four distinct agentic systems against the EEBD-v1:
Agent-E [4]: Our first version of the web navigation agent (in open source) demonstrating expertise in multimodal web interaction.
Emergence Orchestrator: Our proprietary system features a multi-agent architecture. It builds on a Web Agent (a newer and more capable version of Agent-E) for its web navigation and UI interaction capabilities, alongside an API connector agent capable of discovering and making API calls, and an array of agents with other capabilities. The orchestrator layer determines the optimal execution path (UI vs. API) based on the task and the individual agent capabilities.
Anthropic's Computer Use Model [1]: An agent designed for general computer control based on natural language instructions, primarily operating via UI interactions.
OpenAI's Operator Model [2]: Representing state-of-the-art agents focused on UI automation and tool use.
It is important to note that only the Emergence Orchestrator utilized both UI and API execution paths. Anthropic’s and OpenAI’s agents and Agent-E were limited to UI-level interactions, reflecting their current default configurations. While this introduces some evaluation asymmetry, the main goal of this work is to show the architectural readiness gap between single-modality and orchestrated agents in handling real enterprise workflows.
For all tests, the agents were provided with the necessary credentials (API keys, usernames/passwords) to access the target platforms (Confluence, JIRA, etc.), ensuring a level playing field focused on task execution rather than credential acquisition. Given the complexity and open-ended nature of many EEBD-v1 tasks (e.g., "research X and write a summary"), robust, fully automated evaluation is challenging. Therefore, we employed manual evaluation by human experts who assessed whether the agent successfully completed the core requirements of each task.
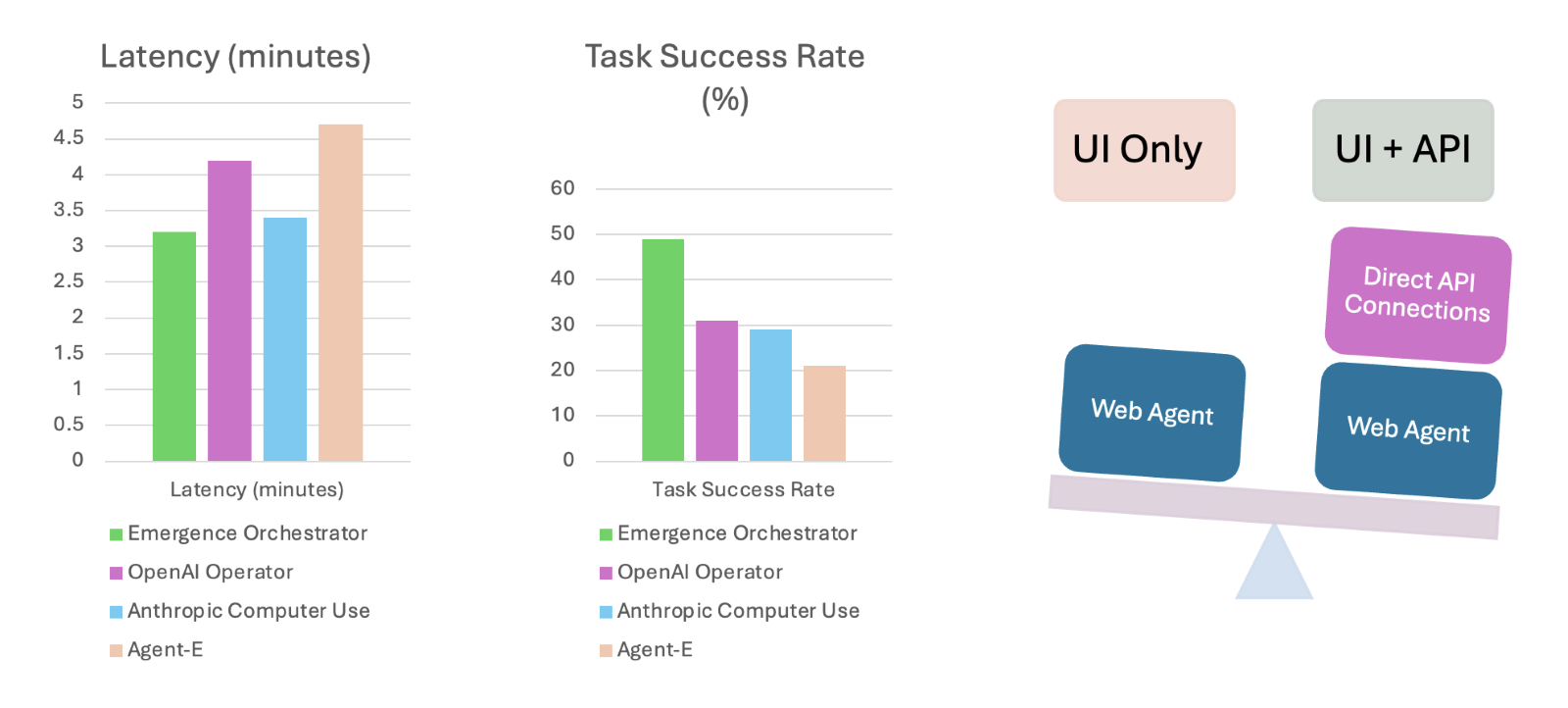
Results: Performance on Enterprise Tasks
Our evaluation yielded significant differences in performance and efficiency across the agents:
Agent
Approximate Task Success Rate (%)
Median Task Latency (Minutes)
Key Observations
Emergence Orchestrator
49
3.2
Leverages Emergence Web Agent for UI and dedicated connectors for APIs, leading to higher success and lower latency.
Anthropic Computer Use
29
3.4
Proficient at UI/API tasks individually, but potentially slower on complex multi-step flows relying on UI.
OpenAI Operator
31
4.2
Similar success to Anthropic, effective but potentially higher latency due to UI focus.
Agent-E
21
4.7
Not equipped with capabilities to perform multi-step API-enabled orchestration for complex enterprise tasks in EEBD-v1, resulting in lower success and the highest latency.
Discussion:
The results highlight several key findings:
API Advantage & Orchestration: The Emergence Orchestrator's significantly higher success rate and lower median latency underscore the advantage of multi-agent orchestration. This system intelligently chooses between UI automation (via its Web Agent) and contextually retrieved and assembled API calls. By leveraging robust API calls where available and minimizing brittle UI interactions, it completed compound workflows faster and with fewer errors, demonstrating the benefit of integrated orchestration.
UI Automation Baseline & Latency: Agent-E [4], operating solely via UI automation as designed, provides a valuable baseline. Its performance illustrates the inherent challenges in success rate and speed when tackling complex, multi-step EEBD-v1 tasks that benefit significantly from API integration or higher-level orchestration. Similarly, Anthropic’s Computer Use [1] and OpenAI's Operator [2], while proficient generalists, also show that relying primarily on sequential UI steps for these complex enterprise workflows can increase latency and potential points of failure compared to UI+API orchestration.
Task Type Matters:
Open-Web Research: All agents, including those primarily focused on web navigation like Agent-E, performed adequately on tasks involving open-web research. This aligns with the strengths of UI automation agents in less constrained environments and reflects the core capabilities Agent-E provides.
Travel Booking: Simple flight booking tasks saw success via both UI and API methods. However, introducing complexity significantly lowered success rates across all agents, indicating challenges with complex reasoning and constraint satisfaction within these domains, regardless of the interaction method.
Compound Tasks (JIRA/Confluence): The Emergence Orchestrator's ability to blend web research (leveraging the capabilities of its advanced Emergence Web Agent, derived from Agent-E [4]) with direct API calls for documentation/ticketing (API) proved highly effective. This combination was key to its higher success rate and lower latency on these multi-step, cross-application workflows compared to approaches limited to UI automation alone.
Conclusion: Moving Beyond the UI into the Enterprise Stack
Our findings strongly suggest that evaluating enterprise AI agents requires moving beyond benchmarks focused solely on web UI interaction. While UI automation is a necessary capability, true enterprise efficiency and robustness often lie in leveraging APIs and potentially even deeper integrations. What EEBD-v1 reveals is not just a performance gap, but an architectural one: the future of enterprise agents depends on their ability to orchestrate across modalities, integrate across platforms, and reason across procedural constraints. Evaluating agents in these real-world conditions, rather than in abstract or consumer contexts, is essential to advancing toward enterprise-grade autonomy.
Future Directions:
The development of effective enterprise AI agents necessitates a co-evolution of agent capabilities, and the benchmarks used to measure them:
Deeper Stack Integration: Future agents should aim to interact not just with UIs and APIs, but potentially with databases, internal services, and other backend systems where appropriate and secure.
Benchmark Evolution: Benchmarks like EEBD-v1 need to expand, incorporating more complex enterprise workflows, stricter policy adherence requirements, and tasks that necessitate interaction with a wider range of enterprise systems and data sources (including databases). Evaluation methodologies must also evolve to handle this increasing complexity, potentially combining automated checks with targeted human evaluation.
Security and Compliance Focus: Enterprise benchmarks must rigorously incorporate security best practices and compliance requirements (e.g., data handling, access control) into task design and evaluation.
By developing agents capable of navigating the full enterprise stack and creating benchmarks that accurately reflect these complex environments, we can unlock the true potential of AI to automate and optimize work within organizations.
References:
Anthropic. (2024, August 14). Claude 3.5 Models & Computer Use Feature. Retrieved from https://www.anthropic.com/news/3-5-models-and-computer-use
OpenAI. (2024, October 1). Introducing Operator. Retrieved from https://openai.com/index/introducing-operator/
H Company. (Accessed 2025, April 10). H Company. Retrieved from https://www.hcompany.ai/
Emergence Agent-E (Version April2024): Mastering Web Navigation with Multimodal Expertise. arXiv preprint arXiv:2407.13032. Retrieved from https://arxiv.org/abs/2407.13032
Zhang, H., Geng, Y., Xu, H., Lin, D., Chen, Z., & Wan, X. (2024). WebVoyager: Building an End-to-End Web Agent with Large Language Models. arXiv preprint arXiv:2401.13919. Retrieved from https://arxiv.org/abs/2401.13919
Zhou, S., Xu, F., Liu, Z., Wang, H., Yin, P., Zhang, H., ... & Liu, Z. (2023). WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv preprint arXiv:2307.13854. Retrieved from https://arxiv.org/abs/2307.13854
Shi, W., et al. (2024). AssistantBench: Evaluating Large Language Models as Assistants. arXiv preprint arXiv:2406.02530. Retrieved from https://arxiv.org/abs/2406.02530
Liu, X., et al. (2023). AgentBench: Evaluating LLMs as Agents. arXiv preprint arXiv:2308.03688. Retrieved from https://arxiv.org/abs/2308.03688
Yu, T., et al. (2018). Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. arXiv preprint arXiv:1809.08887. Retrieved from https://arxiv.org/abs/1809.08887
Gao, Y., et al. (2025). PaperBench: Evaluating AI's Ability to Replicate AI Research. arXiv preprint arXiv:2504.01848.
Zhang, Z., et al. (2025). MLGym: A New Framework and Benchmark for Advancing AI Research Agents. arXiv preprint arXiv:2503.11634.
Wang, Z., et al. (2024). ST-WebAgentBench: Evaluating Safety and Trustworthiness of Web Agents in Enterprise Contexts. arXiv preprint arXiv:2410.06703. Retrieved from https://arxiv.org/abs/2410.06703
A structured five-layer framework provides standardized benchmarking for AI agent capabilities across the full spectrum of enterprise task complexity, from UI to infrastructure.
Emergence’s Agents platform is evolving into a system that can automatically create agents and assemble multi-agent systems withminimal human intervention.
Connecting downstream enterprise applications to the world of external services is crucial, but navigating the vast API landscape can feel like exploring an uncharted jungle.

.jpg.png)