
Benchmarking of AI Agents: A Perspective
Introduction and Importance of Benchmarks
Benchmarking is a vital practice in the IT industry, serving as a tool to evaluate and compare the performance of hardware and software systems against standardized metrics. It compares performance, guides purchasing decisions, and sets industry standards. Benchmarking evaluates systems against standardized metrics and datasets ensuring that they are reliable and trustworthy.
The rapid advancement of artificial intelligence (AI), and more specifically the development of AI agents, ushers in a new era of AI transformation of the enterprise. With the growing enterprise interest in boosting productivity using AI agents, developing suitable benchmarks has become a critical need to ensure that agents meet standards for performance, compliance, and reliability.
Historically, major technological advancements that became mainstream have been supported by rigorous efforts on benchmarks. For instance, the IT industry has witnessed a range of benchmarks from processors to transaction processing systems that drove focused development of high-performance enterprise-grade systems:
- SPEC CPU Benchmarks: Measures processor performance (e.g., SPECint, SPECfp).
- LINPACK: Assesses computing power, used in supercomputer rankings (TOP500).
- 3DMark: Evaluates GPU performance for graphics rendering.
- TPC Benchmarks: Tests database transaction processing (TPC-C) and query performance (TPC-H).
The scope of benchmarks can vary widely. In the context of AI agents, benchmarks play a crucial role in accelerating deployment across enterprises by providing a structured framework to evaluate and improve agent performance. Key objectives include:
- Objective Performance Validation: Establish clear, deterministic benchmarks to assess AI agent performance, ensuring results are consistent and meet enterprise reliability standards.
- Guided Development and Innovation: Use benchmarks to pinpoint specific areas for improvement, fostering agility in development and driving continuous innovation aligned with enterprise needs.
- Enterprise Compliance and Fairness: Implement benchmarks that ensure AI agents adhere to standards of fairness, interoperability, and compliance with enterprise-specific regulations, enhancing trust in AI-driven processes.
- Informed, Reliable Decision-Making: Benchmarks provide an objective basis to users for decision-making, enabling enterprises to verify performance claims and make confident, informed choices that support operational scalability and maintainability.
To design effective benchmarks, we must first understand the unique challenges posed to and by AI agents in enterprise environments.
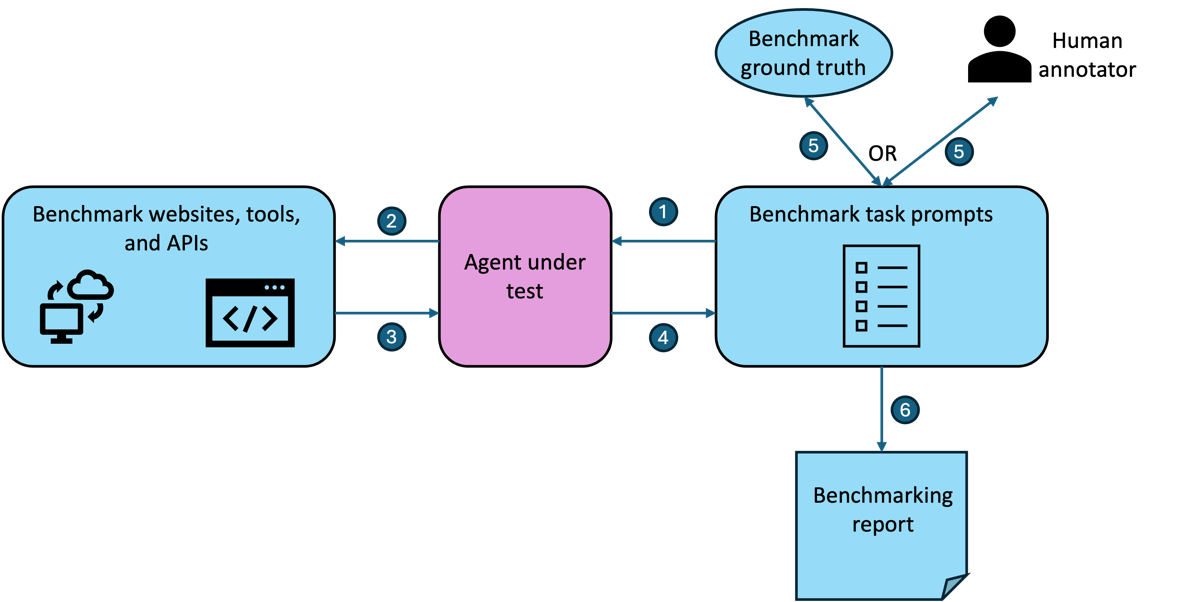
Challenges in creating a benchmark for AI Agents
Creating good benchmarks for AI agents is not easy. Given the stochastic nature of systems developed on the advancements in AI, notably LLMs (Large Language Models), VLMs (Vision Language Models) and LMMs (Large Multimodal Models), reproducibility and standardization of solution paths is highly challenging.
We now discuss a few considerations when creating benchmarks for AI agents:
- Diversity of AI Tasks and Domains: AI agents operate across diverse modalities, including natural language processing, computer vision, and speech, as well as various domains such as finance, healthcare, education, and law. Designing a single benchmark that accurately evaluates performance across such varied tasks, modalities, and domains presents a significant challenge.
- Tool vs Task/Domain vs Skill Centric Approaches: Defining benchmarks requires balancing trade-offs between different perspectives, each offering its own advantages and limitations.
- Task/Domain-Centric Approach:This top-down approach focuses on evaluating an agent's outcomes in the context of specific tasks or domains, rather than focusing on the tools or techniques used to achieve these outcomes. It aligns closely with business objectives, allowing stakeholders to assess results based on their practical impact. However, this method requires extensive benchmarking to cover all possible scenarios, leaving room for certain edge cases to be overlooked.
- Tool/Skill-Centric Approach: This bottom-up approach evaluates the tools and skills an agent needs to perform a wide variety of tasks. It is especially effective when a set of tools (e.g., data science platforms, CRM systems) or operational skills (e.g., web navigation, database management, legacy application usage) is known to be critical within a domain. Benchmarks in this category assess the agent's proficiency with these tools and skills, assuming that diverse outcomes can be achieved by combining these capabilities.
- Pace of Technological Advancement: AI technology is evolving rapidly and hence benchmarks can become outdated very quickly, failing to reflect current state-of-the-art methods and capabilities. Therefore, it is important to ensure that benchmarks keep up with advancements in AI as a continuous process.
- Defining Appropriate Metrics: A benchmark's validity and applicability rely heavily on the metrics used to evaluate AI agents. Defining meaningful performance metrics that capture the nuances of an AI agent's abilities—such as understanding, reasoning, reading and writing operations, the path an agent follows to arrive at a solution, or the creativity of its responses—is critically important. However, some of these aspects can be challenging to quantify objectively.
- Standardization: Given that the area of agentic AI is still in its infancy, reaching an agreement on standardized benchmarks for the enterprise will be a multi-team multi-year effort.
- Bias and Fairness: It is important to ensure benchmarks and metrics are unbiased and do not favor certain models or approaches. Datasets can have intrinsic biases which can affect the fairness and generalizability of the evaluations.
- Reproducibility and Real-World Complexity: AI-driven systems often produce different solution paths from the same inputs due to their stochastic nature, making reproducibility a challenge. Sandboxed benchmarks such as in [1, 2, 3, 4] offer consistent and automatable evaluations but fail to capture the complexity of real-world dynamics. Conversely, real-world benchmarks such as in [5] provide robust testing through dynamic environments, such as live website navigation, but rely on subjective human evaluations due to the lack of automated ground truth. Balancing these approaches is essential for comprehensive and reliable agent assessment.
- Multi-modal and Multi-task Evaluation: As AI agents increasingly handle multiple modalities (text, images, audio) and tasks simultaneously, creating comprehensive and representative benchmarks that effectively evaluate these capabilities across diverse settings can be complex.
- Interpretability and Explainability: It is important to ensure that the benchmarking results are interpretable and actionable. A benchmark should be able to provide a diagnosis to the developer including the actions taken and the reasoning behind them. These insights will help identify the areas of improvement for the agent.
- Risk of Overfitting to Benchmarks: As with any technology, AI agents might be optimized to perform well on specific benchmarks without truly generalizing to broader tasks, leading to inflated performance assessments. Therefore, it is important that custom benchmarks and variants of them are constantly developed to ensure that they are contextualized to the specific enterprises to which they are applied and are free of over-fitting.
Emergence’s approach to creating an industry benchmark for AI Agents
In light of the challenges outlined, we have adopted a focused and deliberate approach to designing benchmarks, prioritizing the following:
- Enterprise Focus: While some progress has been made in developing benchmarks for consumer-focused AI agents, the enterprise domain remains largely unexplored. Enterprise benchmarks present unique challenges due to the sheer variety of tools and domains involved—ranging from 150 to 700 applications in a typical organization. However, addressing this complexity offers immense financial and operational impact, making it a critical area of focus.
- Emphasis on Foundational Capabilities: Given the dynamic nature of enterprise environments—where tools and applications frequently change, and new use cases continually arise—we focus on benchmarking foundational, underlying capabilities. These capabilities, which we refer to as "Skills," are designed to remain relevant despite changes in specific tools or environments. They represent core competencies essential for enterprise tasks and domains, ensuring that benchmarks stay robust and adaptable over time.
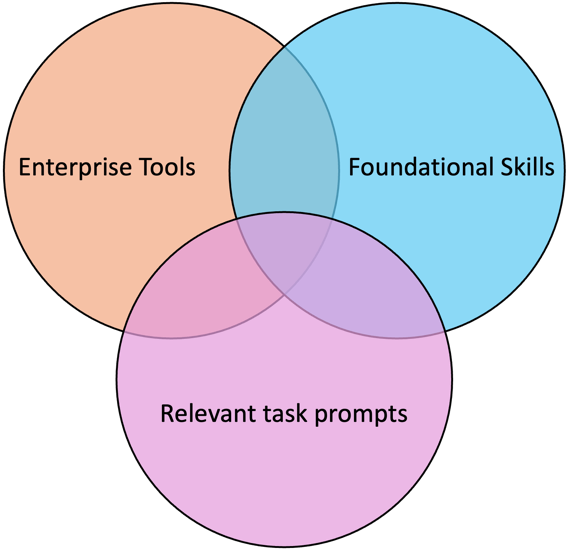
Fig 2: A good benchmark lies at the intersection of good understanding of the enterprise tools, the foundational capabilities needed to operate them and a set of tasks that are relevant to the enterprise
By aligning on the focus above, we’ve arrived at the following benchmarks, which we currently have under development.
- Planning Agent Benchmark: While our planner achieves state-of-the-art (SOTA) performance on the WorkBench [4] open benchmark for planning, existing benchmarks fail to address many skills critical for completing enterprise tasks. We are developing an enterprise-specific planning benchmark that focuses on foundational skills relevant to tasks in domains like CRM, supply chain management, and back-office operations. This benchmark aims to assess planning capabilities in enterprise-representative scenarios.
- Web Agent Benchmark: Using a skill-centric approach, we are creating a benchmark to evaluate the foundational abilities of web agents to navigate, read, write, and update information online. We have identified key skills essential for effective web navigation, and the benchmark tasks combine these skills to test agents on end-to-end scenarios. More details about this benchmark can be found in our paper: [6].
- Text Analysis Benchmark: Text analysis tasks such as document summarization are inherently complex due to the dual challenge of generating high-quality summaries and evaluating their effectiveness. Our work on creating summarization agents for use cases like aspect-based, dialogue-based, and persona-based summarization has provided deep insights into the nuances of good summaries. These insights are being used to design benchmarks that reflect real-world expectations and robust evaluation methodologies.
- API and Tool Agent Benchmark: Large language models (LLMs) face limitations in handling tasks that require real-time interaction with external APIs. While existing benchmarks such as ToolBench [7] and APIGen [8] assess API usage, they often lack generalizability, multi-step reasoning coverage, and stability due to API fluctuations with time. To address these gaps, we are developing SEAL, an end-to-end testbed designed for evaluating LLMs in real-world API scenarios. SEAL integrates standardized benchmarks, an agent system for testing API retrieval and planning, and a GPT-4-powered API simulator with caching to ensure deterministic evaluations [9]. Building on this work, we are developing enterprise-focused API evaluation benchmarks to further assess LLMs’ API capabilities in business-critical contexts.
Practical Actions for Enterprises
With the rapid proliferation of agents, each defined by varying goals and interpretations, enterprises are increasingly challenged to navigate this complex and fragmented landscape effectively. Below are a few key steps Enterprises could take that help determine how they could leverage Agents:
- Define Business Objectives: Start by identifying the specific outcomes you want AI agents to achieve within your organization, such as improving customer service response times or automating data processing workflows.
- Select Key Metrics: Choose evaluation metrics that align with these objectives, focusing on factors like reliability, scalability, and compliance with industry standards.
- Pilot Testing With Existing Benchmarks: Leverage publicly available benchmarks to conduct preliminary evaluations and identify gaps in agent performance.
- Collaborate on Custom Benchmarks: Partner with industry peers or academic institutions to co-develop benchmarks tailored to your domain-specific needs, such as supply chain optimization or CRM efficiency.
- Invest in Automation: Build or adopt benchmarking tools that can automate testing, data collection, and reporting, ensuring consistency and scalability across evaluations.
Conclusion
Benchmarking is no longer just a tool—it has become a key need for the widespread adoption of AI agents in enterprise operations. As these agents take on increasingly critical roles, establishing rigorous benchmarks is vital to provide businesses with objective insights into their performance, reliability, trust and compliance.
References
[1] Yao, S., Chen, H., Yang, J., & Narasimhan, K. (2022). WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. ArXiv, abs/2207.01206.
[2] Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Bisk, Y., Fried, D., Alon, U., & Neubig, G. (2023). WebArena: A Realistic Web Environment for Building Autonomous Agents. ArXiv, abs/2307.13854.
[3] Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., & Yu, T. (2024). OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. ArXiv, abs/2404.07972.
[4] Styles, O., Miller, S., Cerda-Mardini, P., Guha, T., Sanchez, V., & Vidgen, B. (2024). WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting. ArXiv, abs/2405.00823.
[5] He, H., Yao, W., Ma, K., Yu, W., Dai, Y., Zhang, H., Lan, Z., & Yu, D. (2024). WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. Annual Meeting of the Association for Computational Linguistics.
[6] Kandasamy, S. K., Adissamangalam, S., Raj, A., Chinnam, L. V., Radhakrishnan, R., Choudhary, S., Parasabaktula, J., Shalini, P., & Dey, P. (2024). E-Web: An Enterprise Benchmark for Web Agents.
[7] Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., Zhao, S., Tian, R., Xie, R., Zhou, J., Gerstein, M.H., Li, D., Liu, Z., & Sun, M. (2023). ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. ArXiv, abs/2307.16789.
[8] Liu, Z., Hoang, T., Zhang, J., Zhu, M., Lan, T., Kokane, S., Tan, J., Yao, W., Liu, Z., Feng, Y., Murthy, R., Yang, L., Savarese, S., Niebles, J., Wang, H., Heinecke, S., & Xiong, C. (2024). APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets. ArXiv, abs/2406.18518.
[9] Kim, W., Jagmohan, A., & Vempaty, A. (2024). SEAL: Suite for Evaluating API-use of LLMs. ArXiv, abs/2409.15523.
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
