
Benchmarking AI Agents: Key to Building Trust and Driving Scalable Enterprise Adoption
As enterprises increasingly embrace AI agents to drive productivity and streamline operations, a pivotal question emerges: How do we ensure these agents deliver reliable, compliant, and scalable performance in real-world scenarios? Enter standardized benchmarks—a practice that has historically propelled technological advancements, now poised to revolutionize the adoption of AI agents in enterprise settings.
The Case for Rigorous Benchmarks
In the world of IT, benchmarks such as SPEC CPU, TPC, LINPACK, 3DMark, etc., set the standard for evaluating hardware and software performance. Similarly, enterprise-grade AI agents require structured benchmarks to validate their capabilities. Enterprises operate in complex environments with diverse tasks, tools, and regulatory constraints. Without standardized metrics, decision-makers risk deploying agents that fail to meet critical performance and compliance thresholds.
Unique Challenges in AI Agent Benchmarking
Creating meaningful benchmarks for AI agents isn’t as straightfor ward as doing so was for traditional systems. AI agents operate in dynamic, multimodal environments, where reproducibility and fairness are often elusive.
For example:
Bias and Fairness: Intrinsic dataset biases can skew evaluations, necessitating vigilance to ensure fairness across metrics.
- Bias and Fairness: Intrinsic dataset biases can skew evaluations, necessitating vigilance to ensure fairness across metrics.
- Task Diversity: From automating customer support to processing financial data, agents must adapt to tasks spanning multiple domains.
- Pace of Innovation: AI evolves rapidly, making benchmarks obsolete if not continuously updated.
Skill-Centric Benchmarks: Future-Proofing AI Agent Evaluation
To address these challenges, enterprises should focus on foundational skills rather than specific tools. In our paper titled “E-Web: An Enterprise Benchmark for Web Agents” https://shorturl.at/TW9er we discuss a novel benchmark built from foundational principles. The Benchmark advances the state of the art in Enterprise Agent benchmarking. In the related whitepaper, we dive deep into challenges and design considerations in developing benchmarks for Agents. We also explore our efforts in developing different classes of benchmarks.
Skills such as planning, API interaction, and web navigation remain relevant across changing environments, and they ensure that benchmarks assess capabilities critical to long-term scalability. For example:
- A Planning Agent Benchmark could evaluate how well an agent adapts to CRM or supply chain scenarios, working across information spread in multiple systems within the Enterprise, ensuring alignment with operational priorities.
- A Web Agent Benchmark might test an agent's ability to read, write, and interact effectively across multiple online platforms. It could also evaluate how well the agent functions with specific Web technologies such as Shadow DOMs, dynamically generated Web pages, different combinations of Web elements such as text boxes, data pickers, sliders, etc.
Actionable Insights for Enterprises
Adopting benchmarking as a strategy isn’t just about evaluating agents; it’s about fostering innovation and trust in AI Agent deployments. To maximize the impact and minimize the risks of AI deployment, enterprises should focus on the following strategies:
- Define business-specific objectives and select relevant metrics for their own workflows.
- Collaborate with peers, vendors, and/or academia to create domain- and enterprise-specific benchmarks. There is no such thing as a one-size-fits-all benchmark.
- Leverage a combination of automation tools and human oversight to maintain consistency and scalability in agent evaluations.
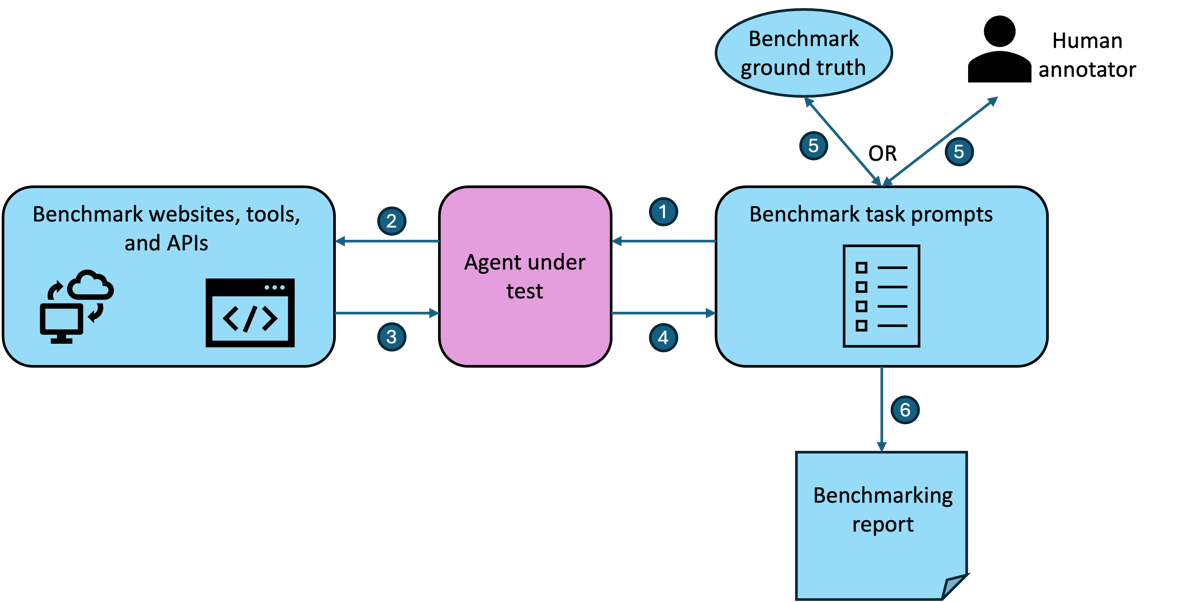
Fig 1: A typical benchmarking approach into which enterprises might invest to ensure agents are evaluated properly.
The Path Forward
In the fast-evolving landscape of AI, benchmarks have shifted from being a luxury to an indispensable foundation for enterprise success. As organizations refine their strategies, those who lead in benchmarking will not only minimize risks but also drive the next wave of innovation and transformation in their industries. To stay ahead, enterprises should take immediate steps to define their benchmarking priorities, collaborate with industry peers, and invest in robust evaluation frameworks that align with their strategic objectives.
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
