
Our Agent-E SOTA Results on the WebVoyager Benchmark
Introduction
Intelligent agents are showing promise in transforming interactive software by improving multi-step task automation significantly across diverse digital environments. While the notion of software agents is decades old, AI-driven agents have recently received renewed interest after the enormous success of LLMs. These AI agents could be incrementally deployed in existing software systems, or one could envision a radical rethink of agent-based systems from scratch. In either case, software systems designed with Agents-in-the-loop (“agentic” systems) are typically designed with a set of predefined skills, each of which involves performing a specific task semi- or fully-autonomously within the target environment.
One of the main focus areas for us has been automation of software applications and solutions that have Web interfaces. In a previous blog, we discussed various capabilities of our state-of-the-art Web navigation agent, Agent-E [1], whose goal is to automatically execute steps that a human would otherwise execute on the Browser interface. Specifically, a combination of appropriately prompted and tuned LLMs, and capabilities such as DOM Distillation and Skill Harvesting make Agent-E compute efficient, low on latency, and cost-effective.
Recent work has published a representative benchmark called WebVoyager [2] which was introduced together with WebVoyager Agent, which is based on a Large Multimodal Model (LMM). It consists of Web navigation tasks across 15 websites listed in the figure and each website has about 40 tasks resulting in a benchmarking dataset of 643 tasks. These tasks could be completed through DOM manipulation (textual) as well as augmenting with image understanding (multimodal).

We evaluated our Agent-E with the WebVoyager benchmark. In this blog post, we present our results that demonstrate that Agent-E beats the state-of-the-art results by 10-30% in various categories of websites. The techniques we use (1) DOM Distillation, (2) Hierarchical iterative planning and (3) skills harvesting, all contribute to the better performance of Agent-E. Furthermore, Agent-E achieves the increased efficacy by just using the text modality and is able to outperform the state-of-the-art results for agents that use both text as well as visual modality.
Brief Architecture Description of Agent -E
Agent-driven systems such as those designed for tasks like browser navigation start with a set of basic, or “primitive,” skills. These skills enable agents to perform actions fundamental to their goals, such as actions required to interact with web content like clicking buttons, entering keystrokes in text boxes, fetching URLs, and retrieving DOM elements based on content type. We introduced this primitive-skill-based browser navigation functionality in Agent-E to build a highly scalable and extensible web navigation platform. Agent-E is also inherently a multi-agent system, with a set of communicating agents performing the tasks. Agent-E is built on top of a multi-agent conversational framework called AutoGen [3]. Agent-E's architecture leverages the interplay between skills and agents (See Figure below).
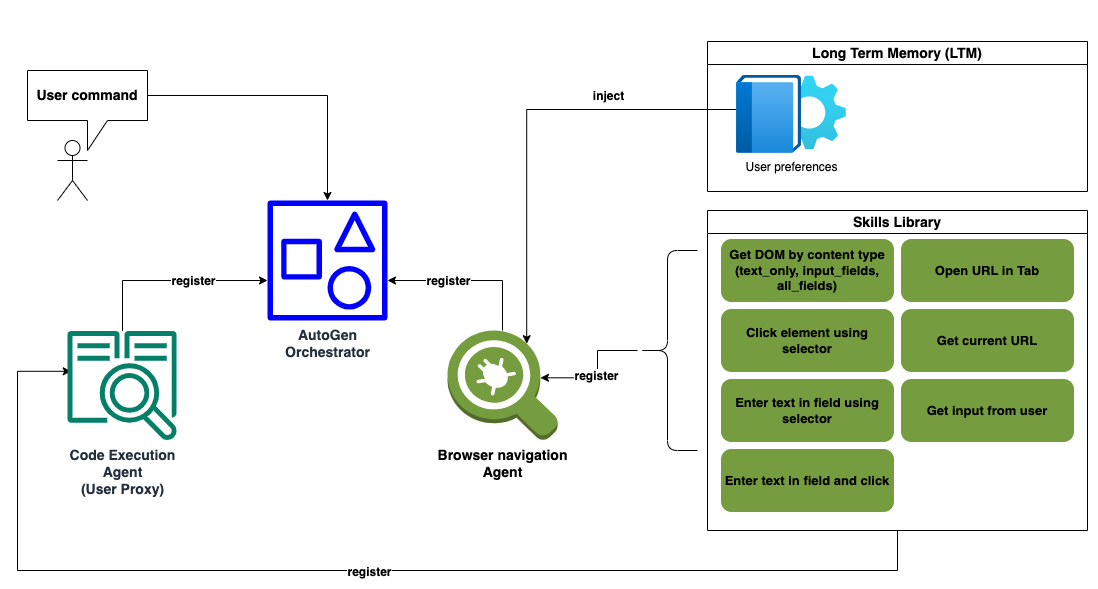
The architecture includes a Browser Navigation Agent and a User-Proxy Agent that coordinate to compose and execute a variety of web workflow automations using multiple primitive skills. Note that this approach allows for the representation of many complex Web workflows using a small number of skills in a Skills Library.
Discussion of WebVoyager Benchmarking Results
WebVoyager is a benchmark that tests an agent’s capabilities for navigation on dynamic live websites. It is more representative than WebArena [4], which is a self-hosted set of generally static websites. WebVoyager consists of tasks such as the ones shown below.

We also compare our results against another SOTA agent called WILBUR [5] which was also benchmarked on the WebVoyager dataset. The benchmarking results are shown in the table below.
- Agent-E: Emergence Agent (text-only capabilities)
- WILBUR Agent: Bardeen AI Agent (text-only capabilities)
- WebVoyager Agent: Tencent Agent (multimodal capabilities)
We see that Agent-E is able to perform significantly more tasks than the other two SOTA agents overall. It performs 10-30% better or equivalent to these agents across most of the categories. There are two particular categories Agent-E performs worse than WILBUR and WebVoyager agents. We understand that this is because there are a number of dropdown menus and dynamic modifications of the web pages where new options are revealed when particular choices are made. In this case, the plan made by Agent-E to execute the tasks goes out-of-sync with the dynamically presented options on the Website.
Agent-E is not currently designed considering a dynamically changing environment, specifically dynamically generated and rendered Web elements. Note that Agent-E’s design is not specific to any Website, but rather to the affordances presented by the environment. In the next version of Agent-E, we plan to address the challenges of dynamically changing environments using more sophisticated planning as well as addressing dynamic DOM updates as part of the execution verification loop.
Conclusion
In this work, we have shown that Agent-E outperforms other state-of-the-art Web agents due to a variety of design choices. More importantly, the WebVoyager agent is a multimodal agent, which means that it has access to screenshots that help in mutually disambiguating the information across text and visual modalities. Agent-E beats this multimodal agent significantly in categories such as Huggingface, Apple, Amazon etc. using only the textual DOM information. Adding multi-modal capabilities to Agent-E will further improve its performance and help us lead towards fully-autonomous Web agents on which humans can rely on to delegate productivity tasks.
References
- GitHub - EmergenceAI/Agent-E: Agent driven automation starting with the web. Discord: https://discord.gg/wgNfmFuqJF
- WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
- AutoGen | AutoGen
- WebArena: A Realistic Web Environment for Building Autonomous Agents
- WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
